最小二乗法メモ
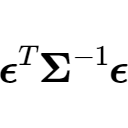
この記事の目的
最小二乗法はとても広く使われていて解説も多数存在しますが、線形空間のみなど簡単な場合についてしか書かれていないことが多いです。より一般化した問題(例えば、3次元回転をパラメーターにもつとき)に適用しようとすると資料が少ないです。この記事では自分の整理用に、より一般化した最小二乗法について記述します。また、なるべく違う文脈で同じ変数を使わないようにし、変数がどんな集合の元なのか、写像の定義域と値域を明記することを心がけます。
なお、私は数学の専門家ではないので、用語や記号の使い方が間違っていたり主張に必要な条件を見落としている可能性があります。
数式の表記
ベクトルは列ベクトルとして行列とともにbold italicで表記します。Lie群またはその元はカリグラフィーフォントで表記します。微分は分子レイアウト(numerator-layout)とします。
Lie群に関連する表記はSola2018にならいます。この文書では
最小二乗法とは
誤差を含む互いに独立な観測値
最小二乗法では、モデルを使った予測値と観測値
ここで、各観測の直積で新たなLie群
重みなし最小二乗法は
係数の
また、
最尤推定との関係
実用上の話
以上の議論で最小二乗法が置いている仮定がいくつか出てきました。
- 各観測は独立
- 残差の分散が既知
- 残差が平均0の正規分布に従う
実際は残差の分布や分散を正確に知ることは困難な場合がほとんどなので、正規分布で近似できるとしてしまって分散は適当に決めた正定値行列にすることが多いです。もっと簡単にして適当な正の定数を並べた対角行列もよく使われます。また、最小化する関数に正の定数をかけてもパラメーターの推定値は変わらないため、分散の全体のスケールは不定でもよいです(相対比がわかっていれば十分)。
ただし注意点は、残差が正規分布からあまりにもかけ離れた分布をしている場合や分散を適切に設定しない場合、求めた推定量は最尤推定量でもなんでもないので、ほぼ意味のない値になります。ノイズの特性がわかっていない問題に対しては、データから残差を計算してプロットした上で分布や分散の異方性を確認し、正規分布で近似できるのか確認してから適用したほうがいいでしょう。とりあえずなんでも最小二乗法を使えばいいというわけではありません。
また、あくまでも最尤推定量なので、そもそも最尤推定が適さない問題に対してはベイズ推定などほかの枠組みを用いる必要があります。
最小二乗法の解法
モデルが線形関数の場合は多くの解説があるので、ここでは非線形の場合について記します。 非線形最小二乗法に対する閉じた形で書ける解は一般にはなく、ほとんどの場合反復法で数値的に解きます1。具体的にはガウス・ニュートン法とその派生のレベンバーグ・マーカート法(修正ガウス・ニュートン法)がよく使われます2。ここでは詳細は他の文献に譲り、Lie群に拡張した上で概要を記述します。
ガウス・ニュートン法
実際は解から遠いときに数値的に不安定になったり収束性が悪い、収束が保証されていないなど実用的ではないので、これに改良を加えたレベンバーグ・マーカート法を用いることが多いです。
次の記事「ガウス・ニュートン法の実装」では、具体例としてパラメーターが線形空間と
-
特定の問題では反復法以外の解法があります。例えば、点群間の剛体変換を求める問題の場合はUmeyama algorithmと呼ばれる特異値分解を用いた有名な解法があります。 ↩︎
-
これらは解の近くで2次収束(1反復で有効桁数が2倍になるということ)が期待でき高速に解くことができるのでよく用いられます。問題によっては(例えば深層学習では)勾配降下法など1次収束の手法も使われます。 ↩︎